浅谈RAG在企业端的落地
0. 引言
RAG相关的技术文章很多。但RAG的落地不仅要理解技术,也要理解业务。
因此我们需要一种兼容的叙事逻辑,既能指引技术迭代方向,也能指引业务发展方向。
先给观点:用“信息”的视角去理解RAG,能更好把握技术与业务结合的脉络。 这里,“信息”是个外延广阔的词,可以泛指:事实、认知、知识等。信息的载体可以是文字、表格、图片等。
信息就像原油,需要提炼加工才能制成商品。基于这个视角可以对现在RAG的应用浪潮做出解读。
业务侧:企业内部有一些结构化或者非结构化的数据,存储了有价值的业务信息,但因为过去分析能力的欠缺,没有创造出商业价值。
技术侧:大模型带来的新变量是逻辑分析能力,同时,RAG为大模型外接了一套信息管理系统。两者结合产生了新的可能性:构建一个通用性强的信息变现系统。
目前比较常见的落地场景是员工培训、客服、销售、资料分析与报告编写等。
想前瞻未来的演化路线,我们需要对信息的生命周期做进一步的分解。这里的拆解借鉴了陆奇对企业数字化的思考[1]:
- 离线过程——信息的采集:
- 获取(Capture)信息
- 表征(Represent)信息
- 存储(Store)信息
- 在线过程——信息的使用:
- 召回(Retrieve)信息
- 处理(Process)信息
- 递送(Deliver)信息
接下来,我会说说自己对每个环节的思考。
1. 离线过程——信息的采集
信息采集的丰富性、全面性、正确性会影响后续分析环节的效果。
业务上需要与客户形成更深入的合作,技术上需要保证解析、表征手段的性能。
1.1 获取(Capture)信息
信息获取环节有不少脏活累活。很容易被轻视,但会是拉开差距的细节点,有一定的壁垒。
我个人判断这里的工作量如果做成产品售卖,足以养活一个小团队。
客户的信息源通常分成两种:
- 结构化信息:数据库、CRM、ERP等
- 非结构化信息:文档、邮件、音视频等
这里重点考虑非结构化的文档,常见如PDF、Word、Excel、PPT等。
文档中的信息主要有几类载体:
- 文字:正文、列表(有序列表、无序列表)、章节(标题、子标题)、引用、公式等
- 图片:图片以及对图片的文字描述等
- 表格:表格结构、表格数据、表格描述等
- 矢量图:流程图、思维导图等
- 文档元属性:文件名、创建人、修改日期、页码等
当前开源的RAG框架有很多,比如Langchain、RAGMeUp、RAGFlow、FlashRAG、Dify等。但大多忽视文件解析的效果。常见就是用PyMuPDF库做一个抽取,不管图片,不处理表格。
以demo为目的,确实不需要对文件解析这个问题太重视。但如果要做大业务规模,这里的投入必不可少。
实际这个环节有很多复杂的工程问题。根源在于PDF这类非结构化数据,是给人看而不是给机器看的,具有很强的视觉属性。常见问题比如PDF的双栏布局、页面旋转(比如发票)、表格的换页分断、水印处理等等。这些都会影响信息采集的准确性和完整性。
解决思路有两个方向,一个是传统路线,比如百度的PP-StructureV2[2],做布局识别与信息抽取;另一个则是直接利用多模态大模型比如GPT-4o的解析能力[3]。
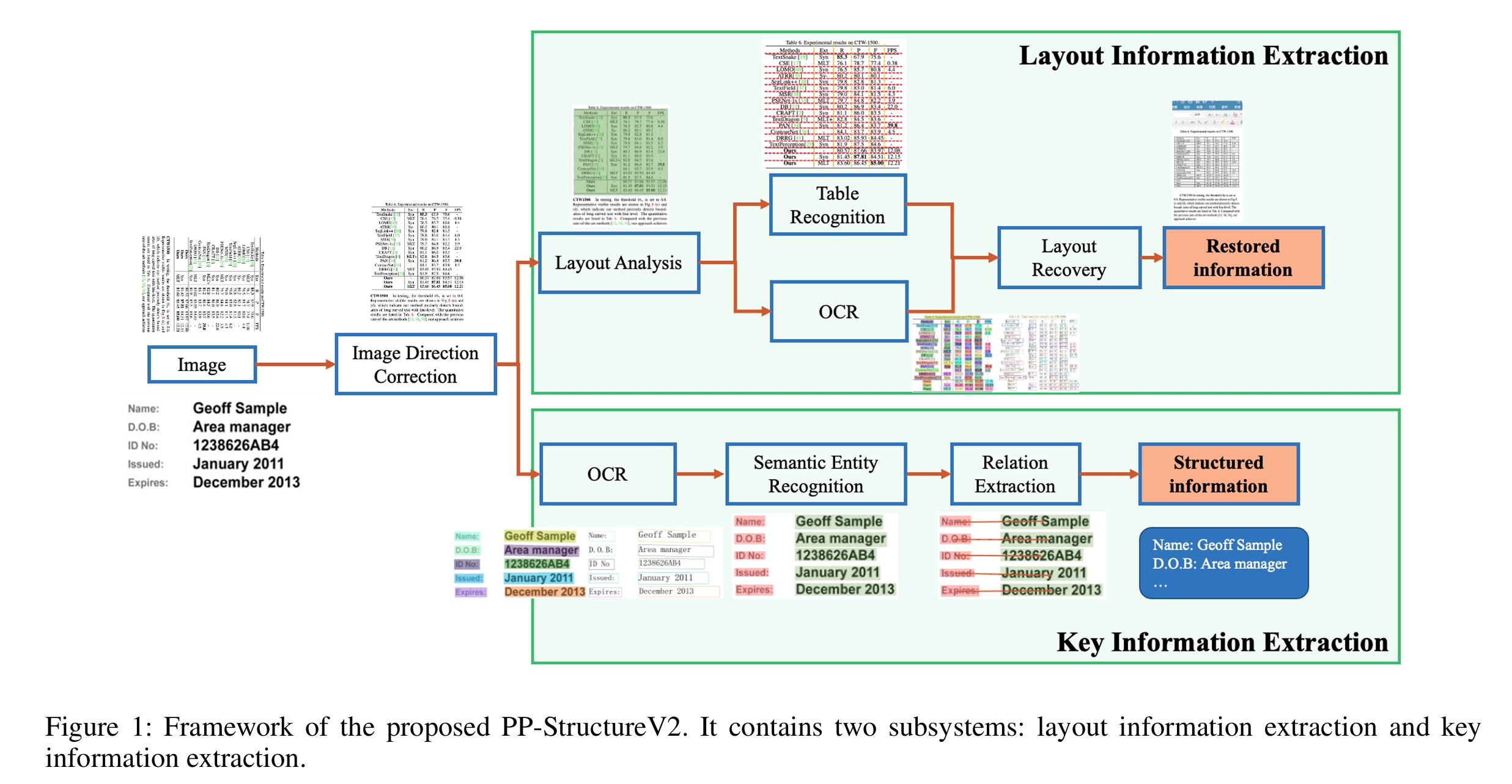
图1. 百度PP-StructureV2的解析框架。
这里还值得思考的是,信息载体(文字、图片、表格等)的业务重要度。站在业务视角看,不同类型业务的主要信息载体也不同。比如操作步骤、流程的业务知识,大量包含于图片之中;分析研究类的业务,大量信息存储在表格中;商品介绍、法律条款等业务,主要以文字存储信息;一些强逻辑性的推理场景,段落结构和引用链也包含了重要信息;文档的元属性也很重要,实践中能带来一些稳定提升。
总的来说,信息的获取(Capture)是最前置的环节,如果产生信息损失或者错误,后续很难弥补。
1.2 表征(Represent)信息
表征信息是为了将上一步获取的信息标准化,以便后续使用。这个环节会对信息做第一次的改造,影响巨大。
当前通用的处理方式是:切片(Chunking)+向量化(Embedding)。我认为这两个动作都值得质疑,都破坏了方案的通用性。但由于技术限制,大家只能捏着鼻子承受,在后面打了一大堆补丁。我一个个来说。
先说切片(Chunking)。因为大模型和向量模型上下文长度的限制,切片是不得不做的无奈之举。但切片动作隐含了两个假设:
- 信息具有局部性。即,相同切片包含同一段语义,不同切片包含不同的语义。
- 用户请求可以在有限的局部信息切块中得到处理。
两个假设在业务上都完全不成立。举个例子,有一本故事情节环环相扣的推理小说,没有人会说“我只要买两页回去就够了”。两页只能回答局部的简单问题,想要了解全局、更深层次的问题,需要看全书。
再说向量化(Embedding)。很多人误认为,只要把文字、图片、表格等所有信息都转成向量,问题就自然解决了。很遗憾,Embedding满足不了这种期待。Embedding的本质是基于数据的统计规律,形成有区分度的聚类。当前开源的Embedding能得到一个还不错的语义聚类效果。但这和业务想要的效果是存在差异的。我举两个例子。
例子1:
- 你是什么职业?
- 张三的职业是老师。
- 我的职业是老师。
- 你的职业是老师。
几乎市面上所有的向量模型,都判定与1的匹配度排名是4>3>2。但有业务场景就是需要让1和2的匹配度最高。
例子2:
- 格力2023年一季度的现金流量表
- 美的2023年一季度的现金流量表
向量模型会认为这两句话很相似,但实际业务场景希望这两句话判定为不相似。
总结上面两个观点:
- 切片动作带来了信息损耗
- 语义向量模型并不能成为通用的业务表征方式
我个人认为long-context未来有机会取代“切片+向量化”,成为更通用的方案。因为大模型能看到无损的信息。但“未来”到来之前,当下只能给“切片+向量化”的方案打上各种补丁,苟延残喘。
打补丁主要有两种方向:1. 信息补充 2. 多重表征。
补充信息:既然切片导致了大量信息损失,那就通过各种方式加回去。比如将文件的metadata塞入每个切片、每个切片前后塞入一些冗余的上下文、对切片做二次聚合(比如LlamaIndex,GraphRAG[4])等。
多重表征:既然语义表征无法满足后续召回的需求,就增加信息表征的形式。比如对切片做摘要、做问题抽取等。
当然,除了补丁,两种动作本身也可以通过一些优化,以降低负面影响。比如切片动作可以尝试基于语义的切分[5]。向量模型训练可以通过指令优化[6]等等。
以上讨论是针对文字。针对以图片、表格为载体的信息,公开文章讨论的并不多。但核心可以有两个思路:
- 多模态匹配:用多模态向量模型转成向量,与文字进行匹配
- 模态转换:用多模态大模型生成一段文字,比如描述、可能的问题列表等
总之,我觉得“切片+向量化”由于有内生性的缺陷,在判断一个业务问题可行性时,通常需要思考这个环节的上限。当然,这种缺陷创造了就业岗位 :P
1.3 存储(Store)信息
这环节有很多细节,但主要是工程架构的问题,和主旨的关联较弱,略过。
2. 在线过程——信息的使用
信息的使用是发挥大模型能力的关键阶段。这里的能力上限决定了系统商业价值的上限。
2.1 召回(Retrieve)信息
“召回”这个术语,容易让人理解成“找出相关信息”。我认为应该反过来理解,应是“排除无关信息”。这是一个去噪的过程。常见的“粗召-精排”模式,是一种多阶段的排除法。
虽说两种解读是硬币的两面,但解读角度的差异能反映理解程度的差异。我们之所以做信息召回,是因为 1. 当前大模型上下文长度有限制 2. 大模型效果不稳定,如果输入有噪声,效果会下降[7]。解决这两个限制的理想情况下,我们不应该有前置的召回环节,而应将所有信息交给能力最强的大模型模块判断,能避免小模型因能力不足导致的信息损耗。
信息召回其实可以用一个函数表达:Relevance(query, information)。
相关性(Relevance)的定义需要回答两个问题,业务追求哪种相关性?何种检索方式更适合建模该相关性?比如,问答类业务追求语义相关,此时往往用混合检索,如BM25+语义向量+稀疏编码[8];营销场景下追求用户需求与商品的匹配,此时更适合外接一个推荐系统;分析类任务对相关性的定义更松,只要主题上的接近即可判定为相关信息。
明确定义后,提升召回效果的思路主要有3种:1. 集成更多、更强的相关性模型 2. query变换 3. information变换。从业务问题出发,倒推这三者有哪些针对性的优化措施。首先一个场景是query中信息缺失。在多轮对话中,用户经常使用指代词,省略一些关键主语或宾语,导致检索模块失效。此时就需要引入问题改写模块,或者对向量模型做对话型的SFT[9];其次是query与information通常在语义空间难以对齐,此时可以考虑query expansion[10]技术,或HyDE[11],生成假答案后用假答案去做匹配;又或者information的存储形态是知识库或知识图谱,就需要做text2sql,text2cypher。
信息召回环节,传统的搜推广技术栈有很多可借鉴的,这里不再赘述。
2.2 处理(Process)信息
信息处理环节是发挥大模型智力的地方。这也是使得RAG系统区别于传统搜推广系统的核心环节。
信息处理分两端,一是对用户query的理解,二是对召回信息的理解。大模型的理解能力在两端都能发挥作用。在query端,大模型可以对原来无法处理的复杂query进行拆解或者进行多轮调度整合得到答案,比如CRAG[12], self-RAG[13];在信息侧,大模型的理解能力使得文本中深层次的语义也可以充分利用。
Agentic RAG[14]是往充分挖掘大模型智力的方向继续迈了一步。给大模型开放了API,甚至是流程调度的权限,授予了信息的“写”权限,想象空间比较大,实际落地我还没想明白。
目前我对这里的思考并不深,以后有机会再详细写。
2.3 递送(Deliver)信息
信息递送就是向用户展现最终的处理结果。信息递送环节主要有两个关键点,一是信息形态,二是时延。
当下主流大模型都是文本大模型,输出是文本,这其实限制了后续向用户呈现信息的选择。知识问答类场景,业务关注点在文档溯源、回复语言风格、精炼度等维度;分析类场景会对输出的Markdown做一层渲染,比如将表格渲染成趋势图等;营销类场景关注话术的销售专业性。我觉得Conversational UI适用的业务场景目前并不广,多模态大模型的逐渐崛起也许能带来新的可能性,但我还没太多思考。
时延是系统能否落地的必要非充分条件。我认为,给定一个大模型后,其单位时间内的智力水平是不变的。因此,时延实质上是一种预算,用户能接受多少时延,决定了系统可以创造的智力总量。强交互场景,时延预算通常不到1秒,此时在不改变基座大模型的情况下,只能做一些调度策略上的调整,或者牺牲交付结果的智力水平;任务型场景的等待周期可以很长,能交付的智能水平可以更高,当下对Agent的研究主要集中在这块。
信息递送部分的业务属性较强,技术侧的选型高度依赖业务。这块也许我遗漏了其它关键点,欢迎补充。
3. 结语
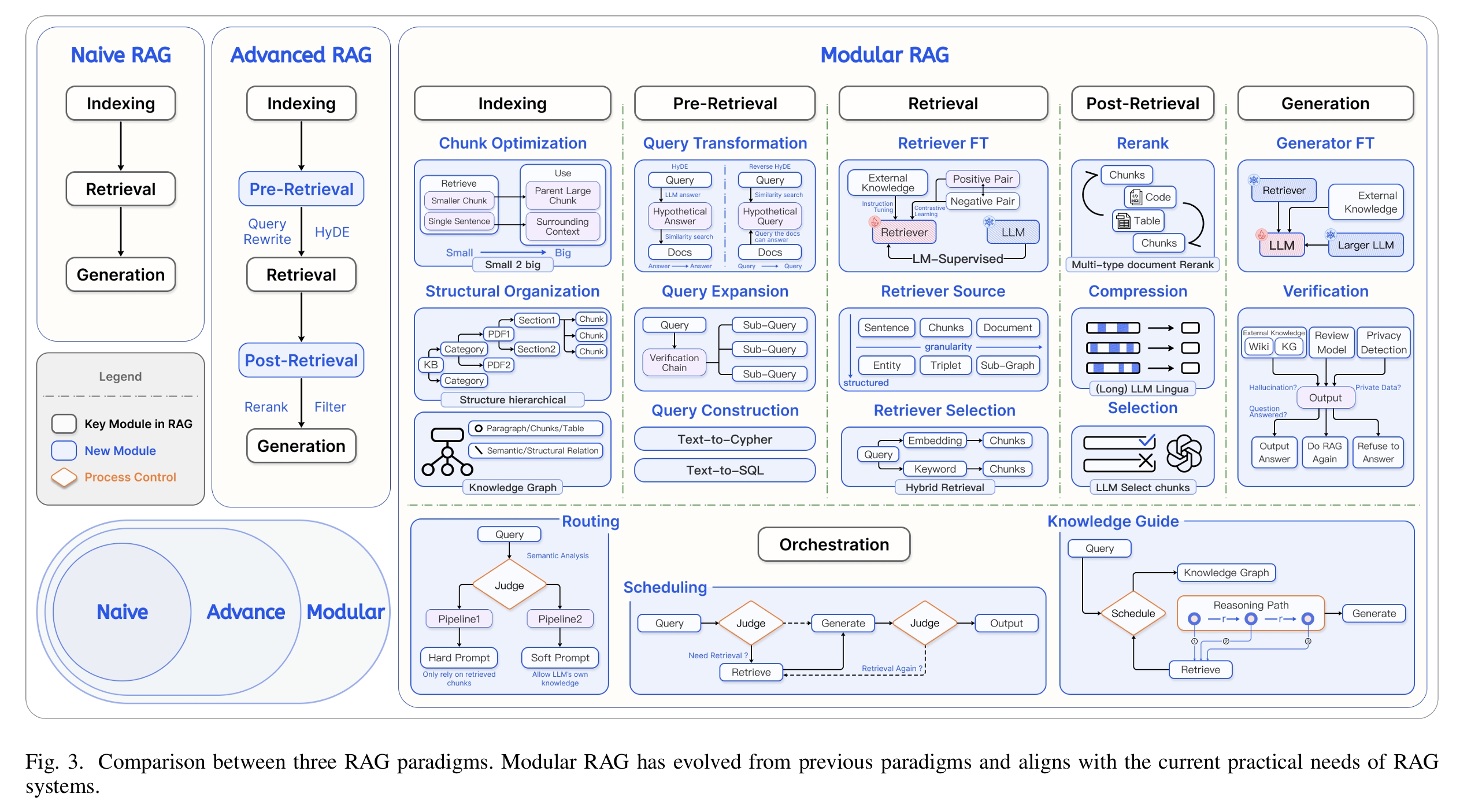
图2. Modular RAG范式图。
本文并非纯技术文章,这方面我认为Modular RAG[15]已经比较全面。我更多是想提供一种业务与技术结合的视角,去思考RAG在企业端的落地。
欢迎讨论交流!
参考资料
[1] 陆奇:任何行业,都值得用数字化再做一遍. https://mp.weixin.qq.com/s/Ax-mnZj6r_QXO2A43XsblQ
[2] PP-StructureV2: A Stronger Document Analysis System
[3] 直接用GPT-4O输出标准化的Markdown https://github.com/CosmosShadow/gptpdf
[4] From Local to Global: A Graph RAG Approach to Query-Focused Summarization
[5] Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation
[6] One Embedder, Any Task: Instruction-Finetuned Text Embeddings
[7] Large Language Models Can Be Easily Distracted by Irrelevant Context
[8] Blended RAG: Improving RAG(Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
[9] Stella模型 https://huggingface.co/infgrad/stella-base-zh
[10] Precise Zero-Shot Dense Retrieval without Relevance Labels
[11] Query Expansion by Prompting Large Language Models
[12] Corrective Retrieval Augmented Generation
[13] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
[14] The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
[15] Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks