NLP多语言模型调研——一个工程视角
本文从工程的视角出发,调研了学术界对多语言模型研究的进展,预计需要20分钟。
1. 背景
在经济全球化的背景下,许多公司开始向海外扩展业务,多语言问题成为了其中一个技术障碍。
1.1 困难
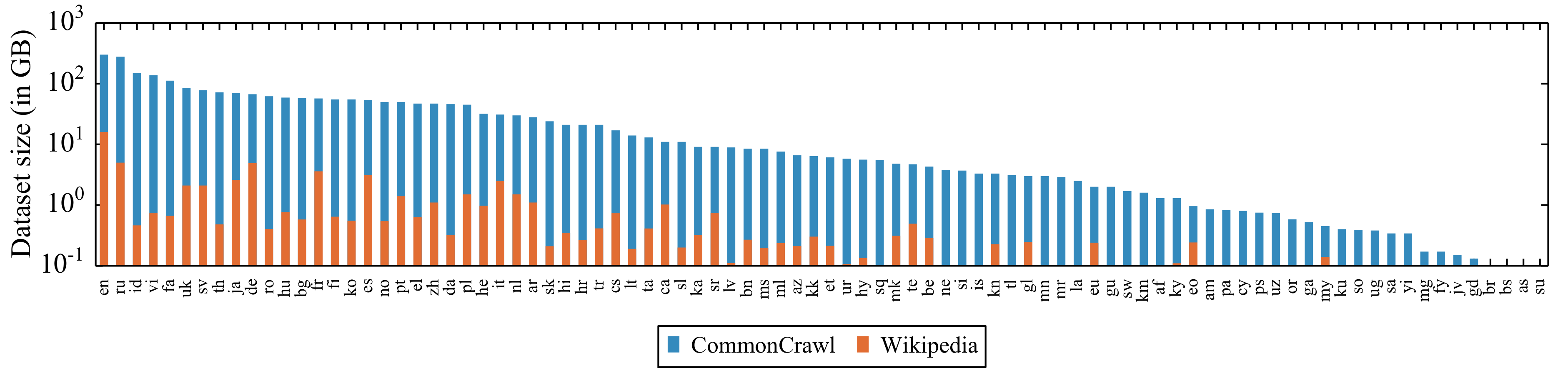
语言多但可用的语料少,导致模型训练困难。全球有超过6000种语言,但常用的仅15种。无监督数据 方面,大多语言的语料资源都不足10GB,见下图;有监督数据 方面,大多数公司在中/英上有一定业务数据的沉淀,但在新语言上的积累基本为零。此外,为小语种招募数据标注人员也存在一定难度,间接限制了有监督数据的获得。数据的匮乏使得在中小语种上训练一个有效的单语言模型变得困难。
图1. 不同语言的语料大小,图自XLM-R1。
除了头部的几个语言,其他语言的资源都仅有几GB、几百MB,勉强在有效训练BERT的边缘。
语言的繁多增加了维护难度、减缓了扩展速度。一方面,模型上线后,不同语言对应的模型需要单独优化、处理bad case;另一方面,倘若没有良好的复用机制,支持一个新语言的周期会比较长,难以适应快速扩展的业务需求。
算法工程师不懂目标语言,翻译工具质量不高,减缓了开发、调试速度。工程中,模型优化的大多收益来自数据的制作与清洗,但这一流程在多语言的设定下变得困难,工程师不懂目标语言使得该过程几乎无法进行。外部翻译软件仅能在一定程度上缓解这个问题,其在小语种上的效果并不可靠,且翻译这一动作本身就极大影响效率。
1.2 目标
解决工程问题的核心往往在于复用与解耦的平衡。从模型生产的角度说,“预训练(pre-training)+ 微调(fine-tuning)”的训练范式很好地把握了这种平衡。在大规模无监督语料上预训练得到的权重,能够尽可能多地被下游任务复用;在小规模有监督语料上的微调得到的模型,则将不同任务解耦。在多语言的语境下,意味着我们在多语言的数据上先预训练,然后针对特定的语言做微调优化。在调研过程中,我仅考虑符合该范式的论文(不然实在太多了!)。
此外,一个有效的调试工具对开发效率有重要提升。翻译的能力则是多语言业务下的一个很好的调试工具,因此我也会关注一些将翻译任务集成到目标函数的工作。
1.3 学界研究简介
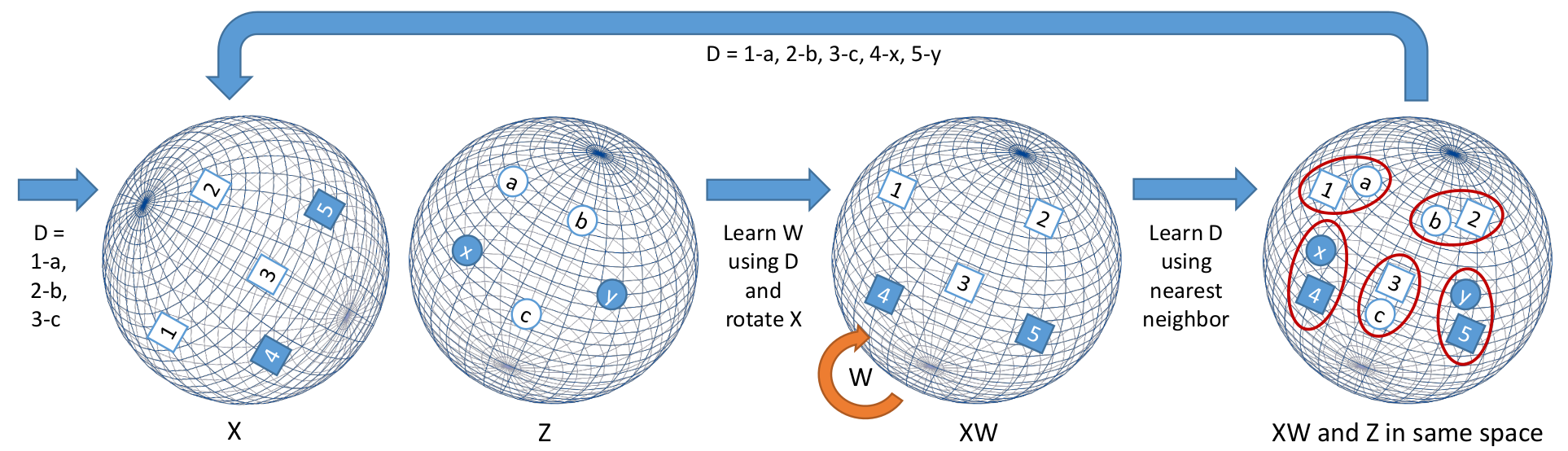
过去的多语言(跨语言)研究更多关注的是两个语言的词向量的对齐,见下图,从而利用富资源(rich-resource)语言的数据提升模型在低资源(low-resource)语言上的效果。
图2. 学习两个语言的词向量之间的映射关系,图自2。
该算法先通过已知字典对齐两个语言的词向量,然后从中挖掘出未知的词向量映射关系。
比如已知对应关系“1-a”、“2-b”、“3-c”,算法收敛后可以知道新的映射关系“4-x”和“5-y”。
BERT3的出现则将大家的研究思路转向“大数据、大模型”。其主要特点是,在大规模无监督的多语言数据预训练,比如Wikipedia、CommonCrawl,得到一个“语言无关”(language agnostic / language invariant)的模型,然后在目标语言上微调,甚至做zero-shot。
在榜单方面,XTREME4是Google制作的一个多语言模型评估基准,对标GLUE,当前已有不少研究工作。数据方面,XNLI、MultiUN、BUCC、Tatoeba、TED等,常见于各类论文。
2. 多语言模型调研
因为数据分布的不同,学术界的研究往往在实际业务上没有很好的效果。因此这里不按照论文,而是按照不同模块来呈现已有的研究成果,以便于选择适合自己业务数据特点的方法。
可以将现有的多语言研究内容拆解成3块:
- 数据处理。包括预处理和数据增广。
- 预训练。目标是学习一个全语言通用的权重。
- 微调。目标是提升模型在目标语言上的效果。
对实际业务应用来说,可能数据处理相关的方法比模型训练更值得参考。
2.1 数据处理
数据处理分成两个部分,数据的预处理和数据增广。
2.1.1 预处理
多语言问题的第一个挑战就是数据预处理。传统情况下,不同语言需要不同的预处理,比如汉语、泰语需要分词;越南语空格区分的是单字,需要连成单词;英语需要考虑将不同时态的词归一化……尽管存在有polyglot5之类的工具提供了一套流程,该过程还是显得繁琐,为部署上线增加了不少麻烦。
因此在论文中,常见使用Byte-Pair Encoding (BPE)、WordPiece、Unigram和SentencePiece(往往和Unigram组合使用)做预处理 。其基本思想都是将语料打散至字符(甚至字节)粒度,然后根据统计信息学习一个合并(或拆分)规则进而缩减(或扩充)词表。Huggingface的文档6对这几种方法做了细致易懂的介绍,这里不再赘述。
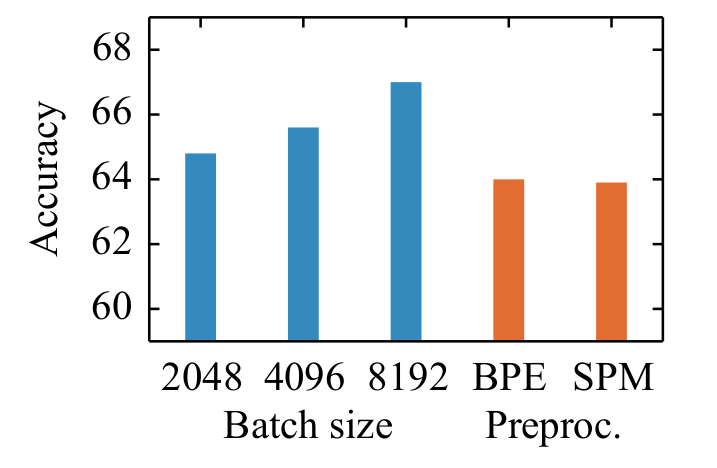
BPE、WordPiece和Unigram都需要预分词(pre-tokenization),而SentencePiece则不需要。在XLM-R1的论文中,作者指出使用SentencePiece和『预分词+BPE』的方法最终的效果并没有特别大的差异,见下图红色柱子。因此,SentencePiece可能是相对较简洁的工程选择。
图3. 不同预处理方式对模型性能的影响。
红色的部分是BPE和SentencePiece的对比,两者并没有明显区别。
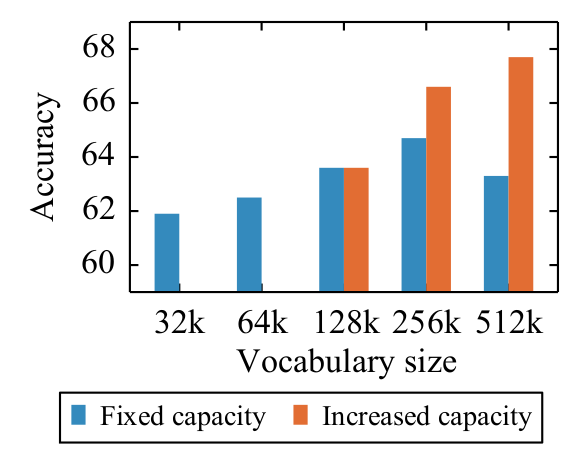
同时,XLM-R1还指出,更大的词表可以带来更好的效果,见下图。而且,一个更大的词表可以使分词后的句子长度变短(因为更多字符被聚在一起而不是打散),降低了输入序列的长度。
图4. 词表大小对模型表现的影响。
在固定模型尺寸的情况下,词表越大效果越好。而且如果同步增加模型尺寸,效果会进一步提升。
此外,富资源语言的数据量大,低资源语言的数据量少,导致在统计的时候,低资源语言的单词容易被打碎成字符粒度(因为频率相对低),因此XLM7和mBERT8都提出在构建词表前,需要对语料做重采样。
2.1.2 数据增广
不少模型的预训练依赖平行语料(parallel corpus)或多语言交互的数据。该类数据比单语言语料(monolingual corpus)稀缺,因此不少论文提出了对应的数据增广手段。
最先能想到的数据增广手段就是翻译,即使用翻译模型,将输入句子或词组翻译成另一种(或多种)语言。该方法较为直观,因此被不少工作采纳,比如VECO9。但翻译模型的质量并不很好,所以,规模小的数据(用于微调)会翻译后找人做审核10,仅保留合格的句子;规模大的情况(用于预训练)则需要通过一些启发式的方式来保证翻译质量,比如回译或多语言翻译结果的一致性11。
除了整句的翻译,XLDA12提出了一种为跨语言模型设计的数据增广方式,其核心思想是将输入文本的一部分替换成另一个语言下的翻译,见下图。该方法可以在多种粒度上进行:在单词粒度上,可以根据双语词典13替换句子中的单词;在词组粒度上,ALM14基于词组表(phrase table)根据概率和启发式规则将句子中的一些词组替换;在句子粒度上,Unicoder15将一个文档中的句子交替替换为翻译。
图5. XLDA数据增广示意图。
最左边表示给模型输入单语言的句子,中间表示分别输入两种语言的句子,最右边表示将单语言句子的一部分翻译成其他语言。
另一种方式数据增广方式是双语句对挖掘(bi-text mining)。LaBSE16通过训练一个简单的CDS(contrastive-data-selection)打分模型,从海量网页中挖掘可能的双语句对,并采样让人类评估,保证优质翻译的占比在80%以上。论文中也提及了数据质量与模型性能的关系,并不意外,如果没有CDS模型过滤,模型在召回任务上的precison@1从99%下降到80%。
2.2 预训练
预训练的目标是获取一个“所有语言通用”的模型权重。当前的研究主要在目标函数和训练方式上改进,模型主体结构还是基于Transformer。
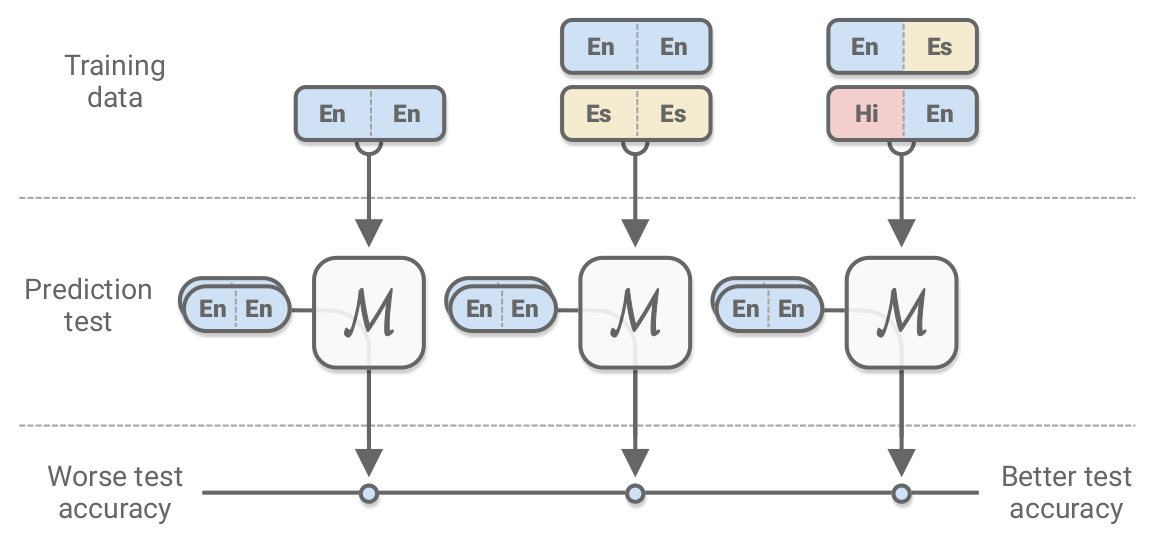
一类研究思路是使用语言模型(Language Model)的目标函数。通常是改造BERT3的MLM(Masked Language Model)。XLM7提出了MMLM(Multilingual Masked Language Model)、TLM(Translation Language Model),ERNIE-M17提出了CAMLM(Cross-attention Masked Language Model),见下图。MMLM的核心是通过让多个语言共享一个编码器(encoder)的参数,从而使得模型权重变得通用,但不同语言的句子之间没有交互。在一篇分析预训练模型跨语言能力的论文中18,作者指出编码器参数的共享是最重要的(大于subword词典或分类层参数的共享)。MMLM只需要非平行语料,而TLM和CAMLM依赖平行语料。TLM会利用输入句子对中一切可以使用的单词,比如在预测中文mask的时候,会同时根据英语和中文上下文(context)进行。CAMLM则只使用另一种语言的上下文作为注意力的对象,即预测中文mask的时候,使用对应英语句子的上下文,且不用中文句子的上下文。
图6. MMLM、TLM、CAMLM的区别,图自ERNIE-M17。
三者的区别在于注意力机制:
- MMLM只关注相同语言的上下文。
- TLM关注所有语言的上下文。
- CAMLM关注另一个语言的上下文。
在InfoXLM19和BERT-Flow20中都解释了为何这类语言模型的目标函数有效。从信息论的角度,语言模型其实是在优化上下文$C$与一个特定单词$\omega$的互信息$\mathcal{I}(C, \omega)$。而跨语言的表达是以单词$\omega$为桥梁对齐的,比如中文上下文$C_{zh}$和英文上下文$C_{en}$之间,通过共现的单词$\omega$构建起了联系。
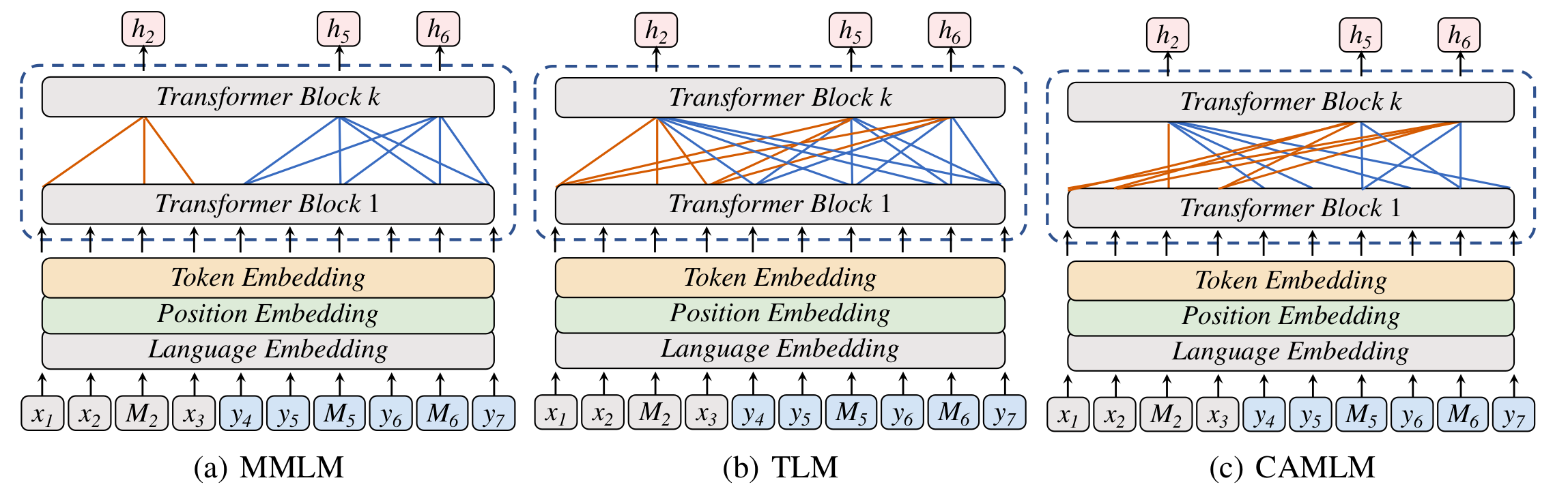
另一类研究思路是引入无监督翻译中常用的回译21(Back Translation)目标函数,比如ERNIE-M17预训练的第二阶段BTMLM(Back-Translation Masked Language Model),见下图。BTMLM分两个阶段:第一阶段是输入完整句子,生成伪平行句;第二阶段是根据mask过后的句子和一阶段中生成的伪平行句,来预测mask处的单词。
图7. ERNIE-M17预训练第二阶段的BTMLM训练示意图。
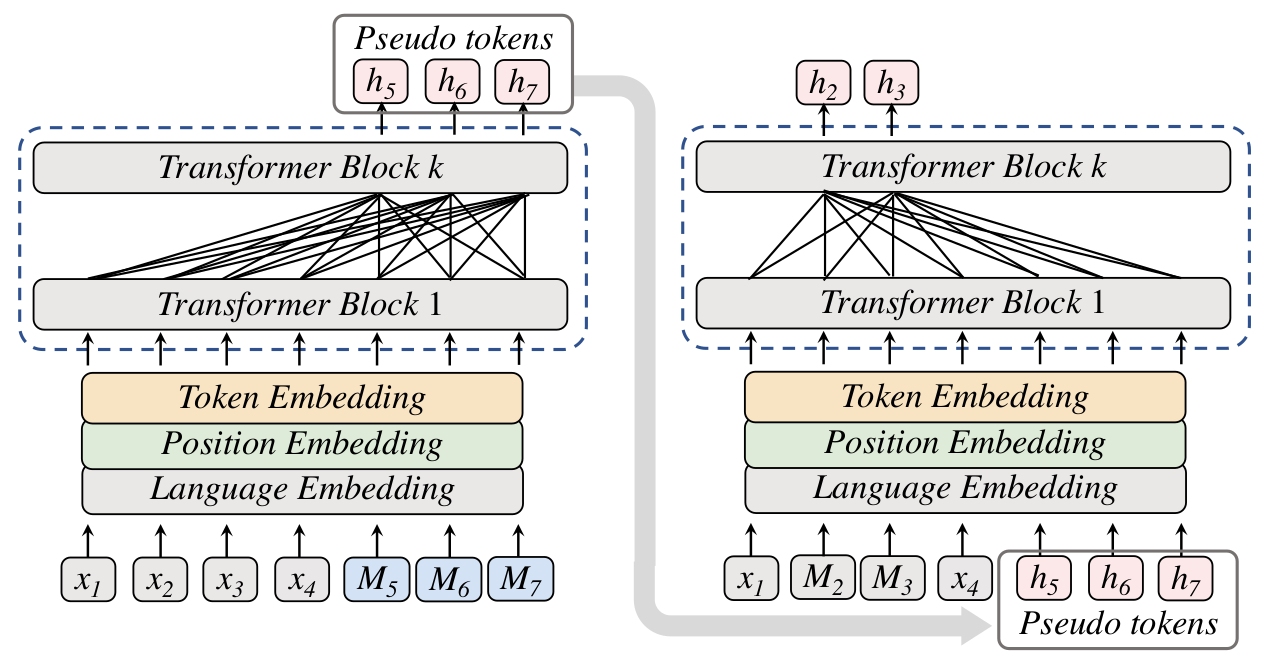
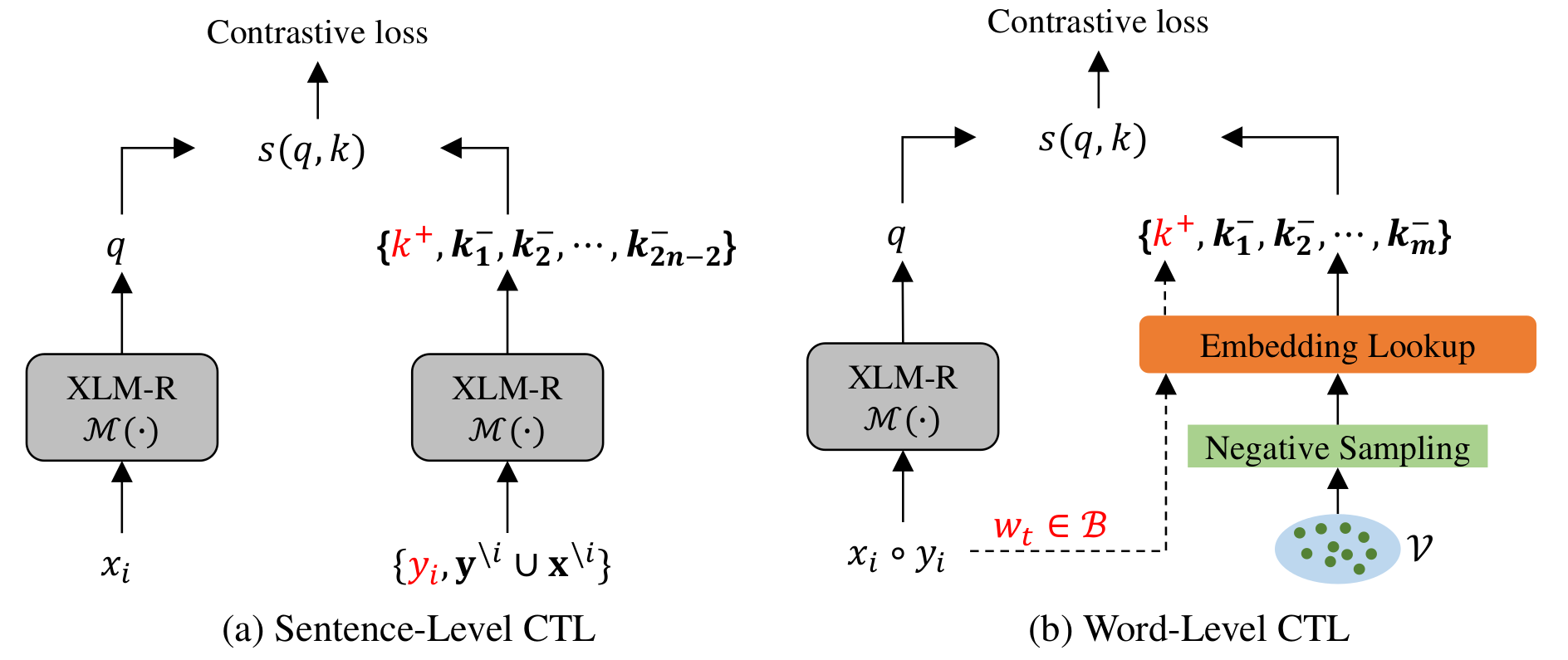
对比学习(Constrastive Learning)也是常见的研究角度之一。在HICTL22中,作者在不同维面(facet)上做对比学习:句子级别和单词级别。HICTL的输入是句子和它对应的翻译(如果有平行语料)或者扰动后的版本(如果没有平行语料)。在句子层面,HICTL让句子与其对应的翻译句(或扰动句)的向量表达尽可能接近,与同一个batch内的其他句子的向量表达尽可能远。同时作者也提出了一种有趣的插值算法,用于构造困难负例(见论文Figure 2);在单词层面,将句对中出现的单词作为正例向量,其它单词作为负例向量。
图8. HICTL中的对比学习。
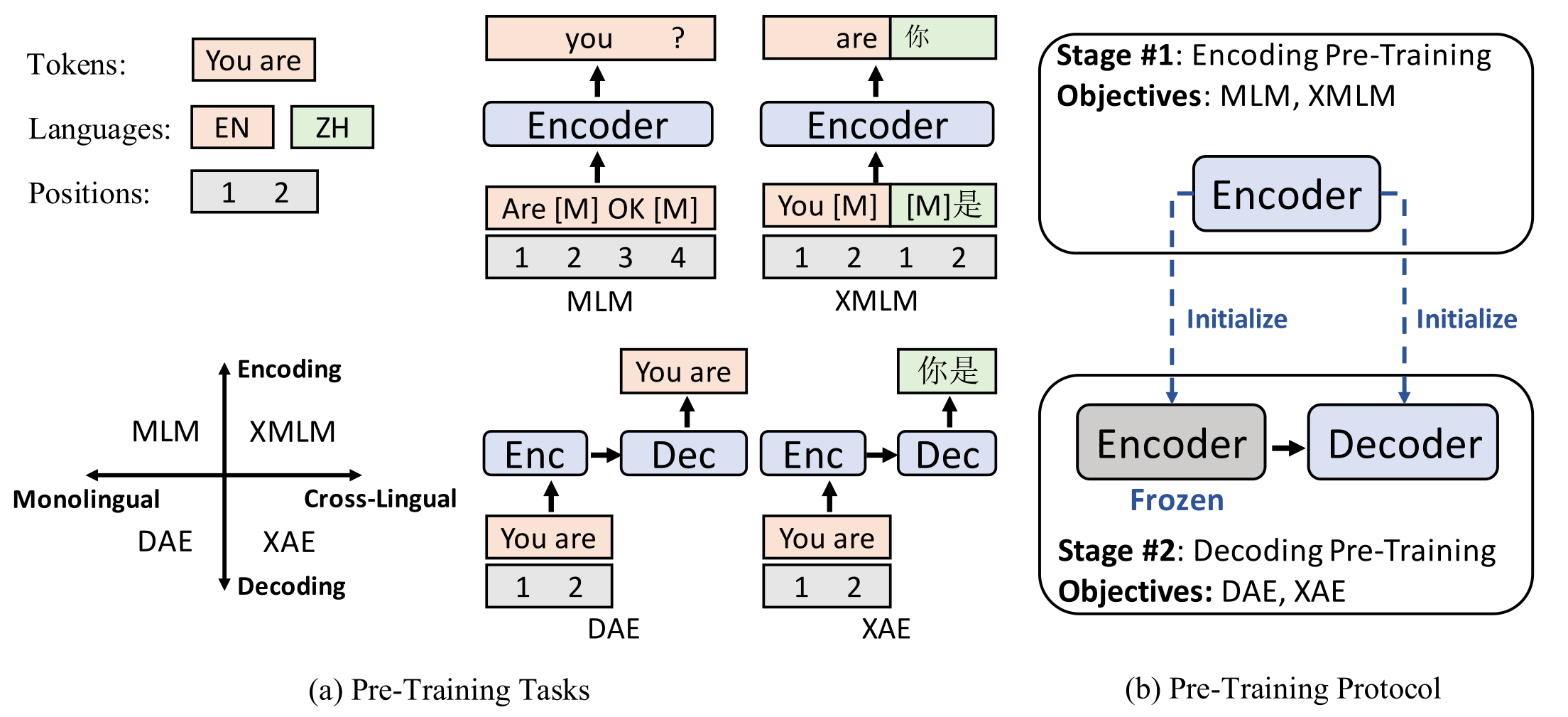
还有一部分研究借鉴了降噪自编码机(Denoising Autoencoder)的思想,比如mBART23和XNLG24。两者的共同点是对输入做扰动并让模型还原出原始句子。扰动操作包括:随机替换单词、打乱单词的顺序、随机删除单词。其中XNLG的训练分成两个阶段,见下图,先用MMLM(即图中MLM)和TLM(即图中XMLM)训练一个编码器,然后用该参数初始化编码器和解码器,并用DAE(Denoising Auto-Encoding)和XAE(Cross-Lingual Auto-Encoding)继续训练。DAE和XAE都是以从扰动句中恢复原句为目标,区别在于DAE是希望还原出原句,XAE是还原原句的翻译。
图9. XNLG的预训练方式。
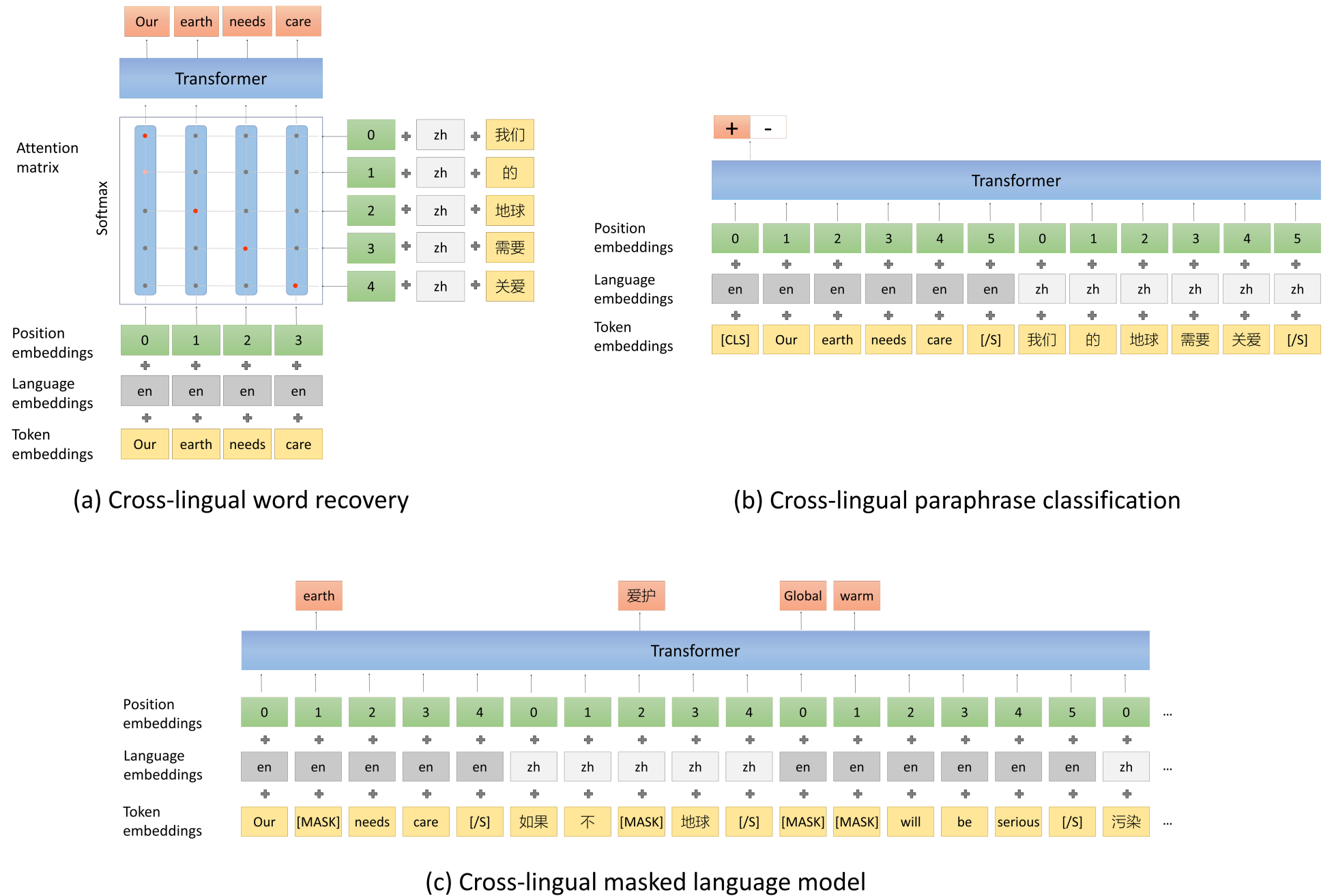
为了实现将不同语言的语义向量对齐的目标,还可以设计不少专门的目标函数。Unicoder15中就构造了3个跨语言目标函数,见下图。跨语言单词还原(Cross-lingual word recovery)的目标是对齐两个语言的单词,其输入是两个语言的注意力矩阵;跨语言同义句分类(Cross-lingual paraphrase classification)的目标是让模型区分两个不同语言的句子是否表达相同语义;最后(c)就是上面说的TLM。
图10. Unicoder的目标函数。
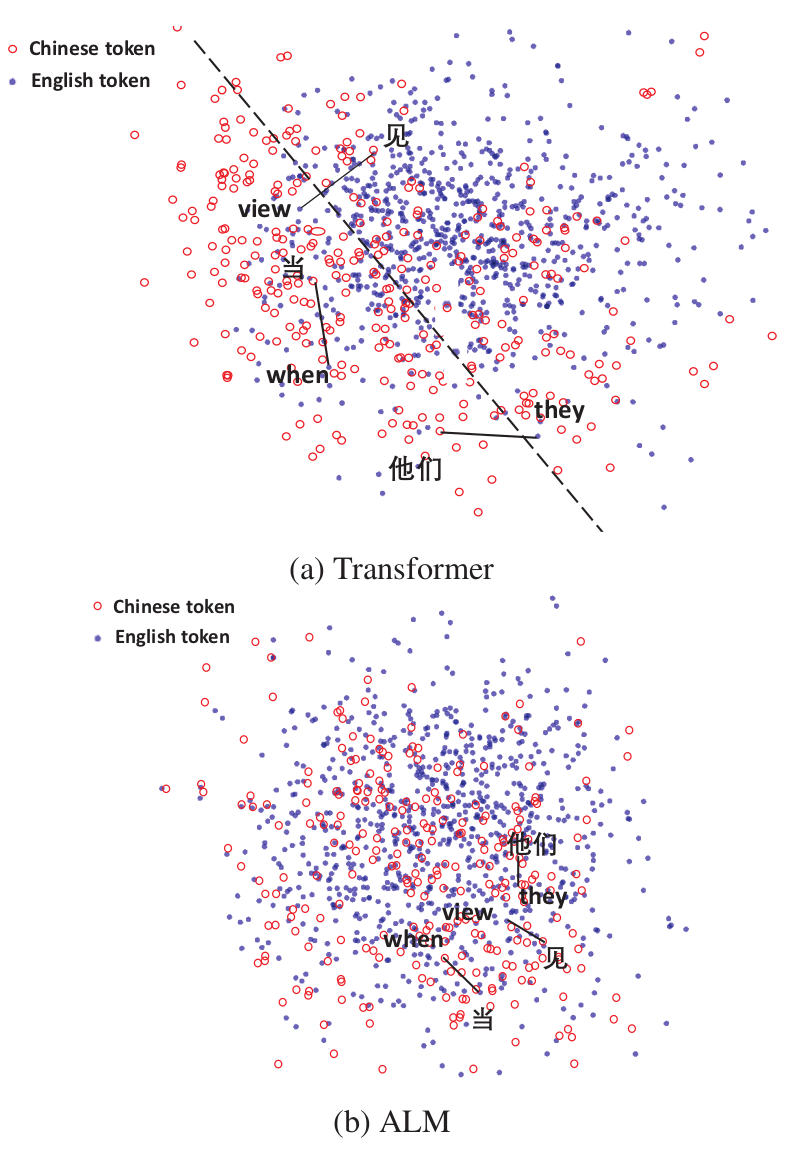
上述的训练方式是否真的能让不同语言的向量在语义空间对齐?ALM的作者做了一个简单的可视化,如下图。可以看到不同语言但相同语义的词向量确实被聚在了附近。这个特点使得计算不同语言的语义向量之间的相似度变得有意义,使我们可以只标注中文的数据,而能为其他语言提供服务。
图11. ALM与Transformer的跨语言词向量对齐情况。
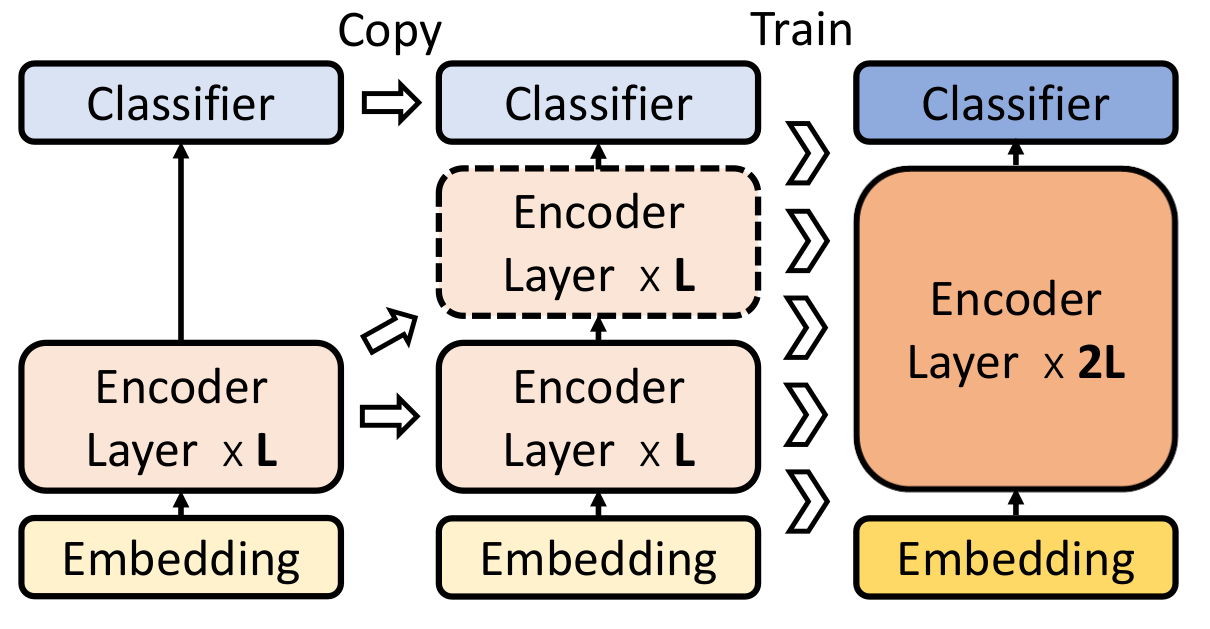
除了目标函数外,训练方式也可以进行改进。LaBSE中采用了Progressive Stacking25的预训练方法:假设需要训练一个$L$层的模型,则首先训练前$L/4$,然后训练前$L/2$,最后训练全部$L$层。其中每次都使用上一个环节的权重来初始化当前环节的模型。
图12. 分阶段预训练Progressive Stacking。
2.3 微调
微调的目标是提高模型在目标语言上的表现,从而达到上线服务的水平。
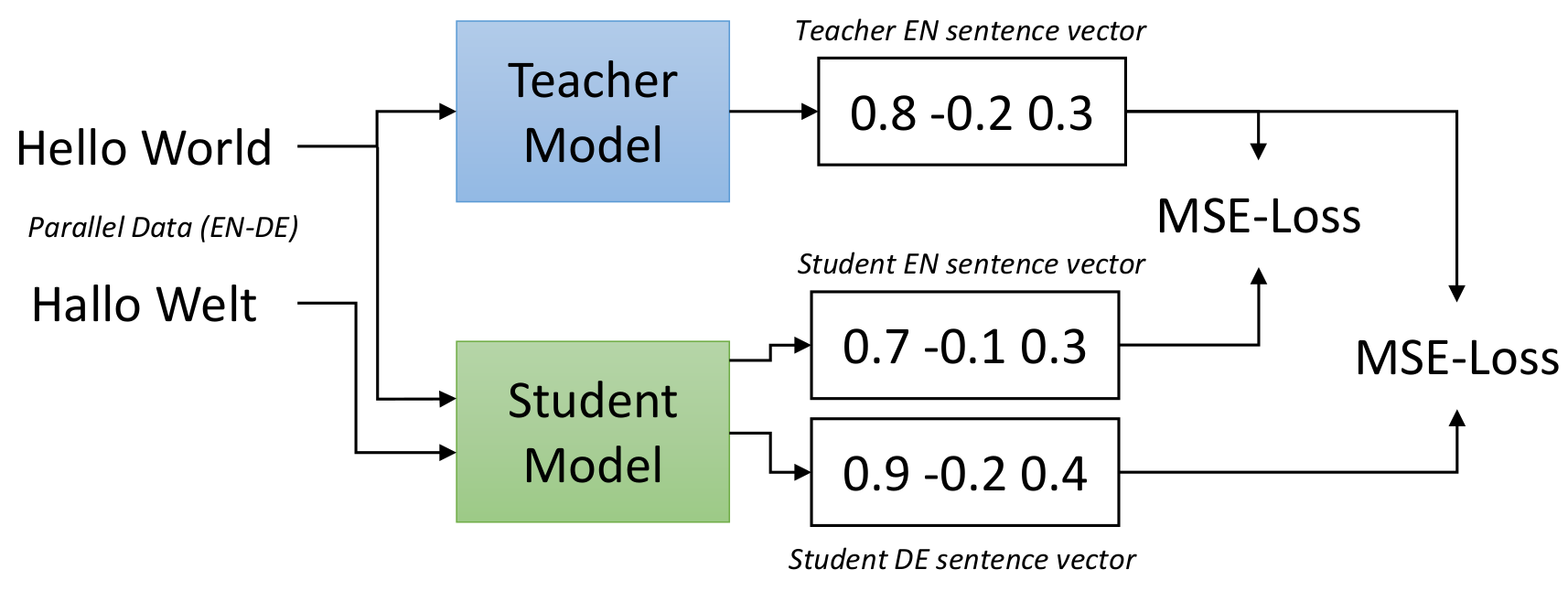
UKPLab提出了一种蒸馏的方案10。作者先在富资源的语言上训练一个单语言的老师,然后将其知识蒸馏给一个用多语言模型初始化的学生,见下图。假设我们的目标语言是德语,则需先用英语数据训练一个老师模型,并用翻译软件将所有英语数据翻译成德语(需要人工审核质量)。对于学生模型而言,目标是让其输出的英语和德语向量与老师模型尽可能接近。
图13. 从单语言老师蒸馏出多语言学生。
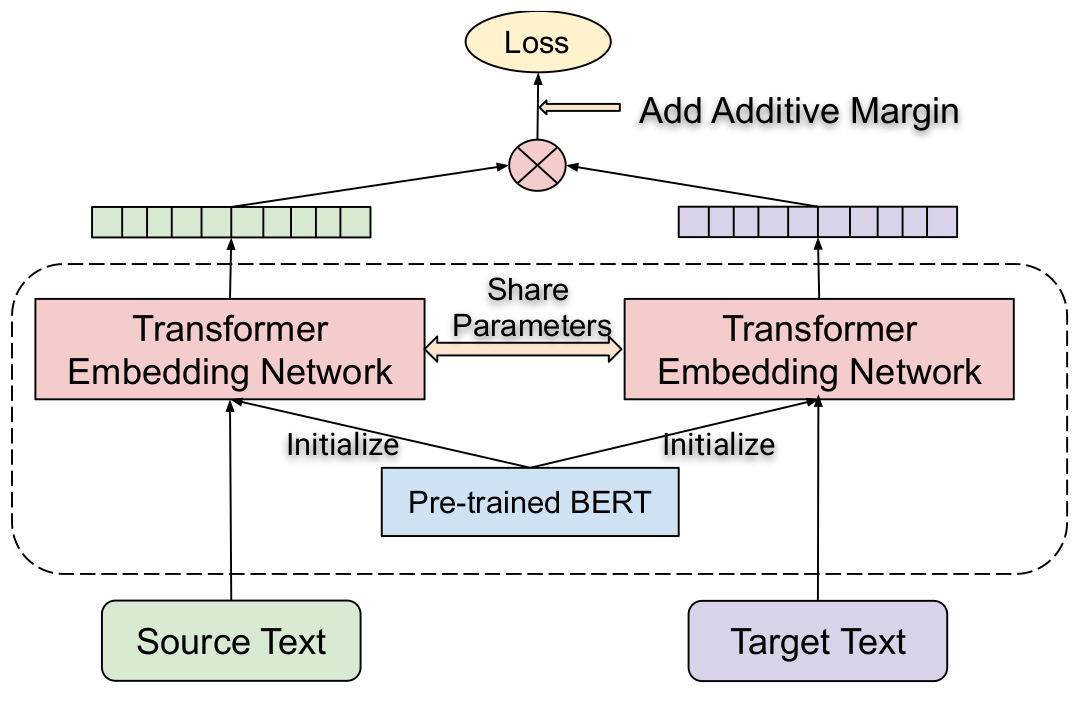
LaBSE使用了Additive Margin Softmax作为目标函数,目标是让一个batch内,句子和它对应的翻译句的余弦距离尽可能接近,与其它句子的余弦距离尽可能远。此外,由于模型较大,占用显存较多,通常batch的大小不会很大。所以作者提出了一种cross-accelerator的负例采样方式,即在多块GPU(或TPU)上,一个batch中的样例会被广播为其它所有batch的负例。
图14. LaBSE的对偶编码器的微调方式。
3. 论文中有用的工程结论
内容太多,这章略过,有空补上。
参考文献
-
Unsupervised Cross-lingual Representation Learning at Scale ↩ ↩2 ↩3
-
Learning bilingual word embeddings with (almost) no bilingual data ↩
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding ↩ ↩2
-
XTREME官网 https://sites.research.google/xtreme ↩
-
polyglot文档 https://polyglot.readthedocs.io/en/latest ↩
-
Huggingface文档 https://huggingface.co/transformers/tokenizer_summary.html ↩
-
BERT训练数据重平衡 https://github.com/google-research/bert/blob/master/multilingual.md#data-source-and-sampling ↩
-
VECO: Variable Encoder Decoder Pretraining for Cross Lingual Understanding and Generation ↩
-
Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation ↩ ↩2
-
A Multilingual View of Unsupervised Machine Translation ↩
-
XLDA Cross-Lingual Data Augmentation for Natural Language Inference and Question Answering ↩
-
Alternating language modeling for cross-lingual pre-training ↩
-
Unicoder: A Universal Language Encoder by Pre-training with Multiple Cross-lingual Tasks ↩ ↩2
-
Language-agnostic BERT Sentence Embedding ↩
-
ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora ↩ ↩2 ↩3 ↩4
-
Emerging Cross-lingual Structure in Pretrained Language Models ↩
-
InfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training ↩
-
On the Sentence Embeddings from Pre-trained Language Models ↩
-
Understanding Back-Translation at Scale ↩
-
On Learning Universal Representations Across Languages ↩
-
Multilingual Denoising Pre-training for Neural Machine Translation ↩
-
Cross-Lingual Natural Language Generation via Pre-Training ↩
-
Efficient Training of BERT by Progressively Stacking ↩